Introduction
As Tezos core developers, we DaiLambda and Tarides are working together to improve the perfomance of Tezos context: the version controlled store of Tezos block chain states.
DaiLambda has Plebeia, an append-only style data storage system based on Merkle Patricia binary tree. It is similar to Irmin by Tarides used for the Tezos context but incompatible. DaiLambda and Tarides have worked together to improve the performance of Tezos context subsystem, sometimes using what we have learned from Plebeia. For example, we provided the context tree for faster file access from the middle of the directory tree. Our context flattening done at Hangzhou upgrade speeded up the node by 30%. Recently, we have worked together to provide efficient Merkle proof encoding of Tezos context, using the idea of extender nodes of Plebeia, which will be used for the layer 2 solutions introduced in Tezos Jakarta upgrade.
Recently Tarides has published bencharmks of Tezos context subsystem. We have extended this benchmark to Tezos+Plebeia, Tezos node using Plebeia for its context subsystem, in order to learn anything in Plebeia can help Tezos context further.
Note on the bencharmk
Please note that this benchmark is not to say which subsystem is superior.
The benchmark has some inevitable bias: for example, Irmin must keep its Merkle hash compatible with the Tezos context hash and therefore has to use inefficient Merkle hash computation. Plebeia has no such restrictions: it can use the optimal hashing algorithm and have many optimization techniques which cannot be used in Tezos context immediately.
The object of this benchmark is to seek such Plebeia optimizations worth to apply for future Tezos context.
Benchmark summary
It is to replay Tezos mainnet 160,000 block context API calls from level 2,080,000 to 2,240,000 of Hangzhou protocol from the snapshot of level 2,080,000.
The benchmark only measures the time and the memory usage of the context subsystems. It replays the context trace, the history of the context API function calls. The other cost factors in Tezos node: the network delay, the computation in the protocol, the store access, etc. are excluded.
Our replay benchmark method is inspired by the one Tarides did. We use our own replay trace recording to support Plebeia context. But they should be very similar.
So far we benchmarked on 3 memory settings (32GB, 16GB and 8GB).
Note that Plebeia is not compatible with the current Tezos storage subsystem using Irmin. It does not produce the same Merkle hashes.
- Benchmark targets
- Benchmark using a 32GB machine
- Benchmark using a 16GB machine
- Benchmark using a 8GB machine
- Observation
- Appendix: how to reproduce the benchmarks
Benchmark targets
- Irmin: version 3.2.1
- Plebeia: commit 794e77c2b3
Tezos+Plebeia branch is used for the benchmark. This branch also contains tezos_replay_trace.exe to replay the context trace data.
Benchmark using a 32GB machine
Machine spec
- Desktop
- CPU: Intel(R) Core(TM) i7-8700K CPU @ 3.70GHz
- Memory: 32GB
- Disk: SanDisk SDSSDH3 1TB
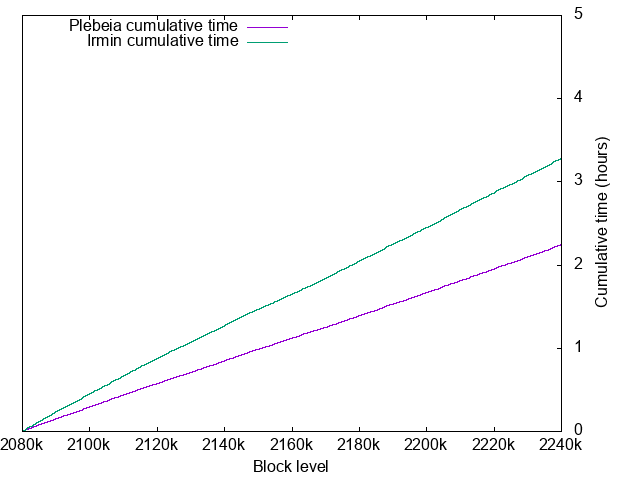
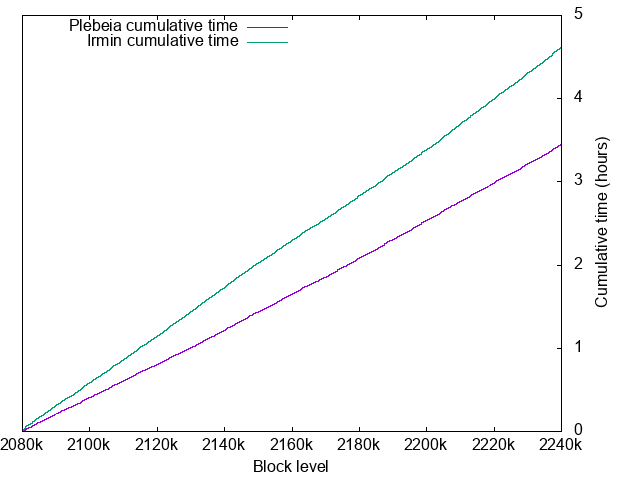
Block processing times
- Plebeia: 2.24 hours for 160001 blocks
- Irmin: 3.28 hours for 160001 blocks
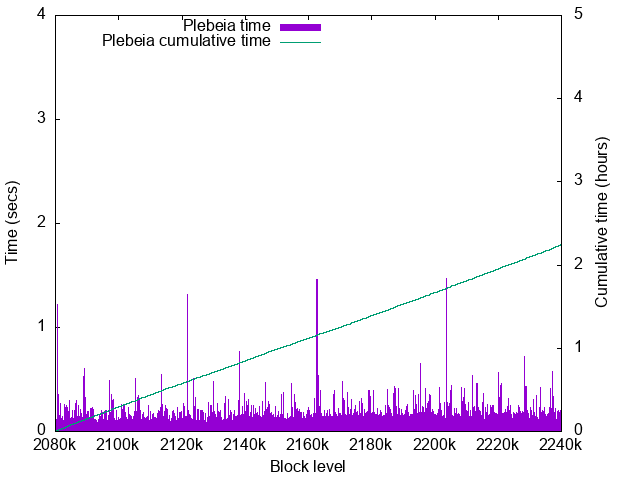
Plebeia time details
- Worst time: 1.47sec, excluding the times for the first blocks.
Irmin time details
- Worst time: 1.58sec, excluding the times for the first blocks.
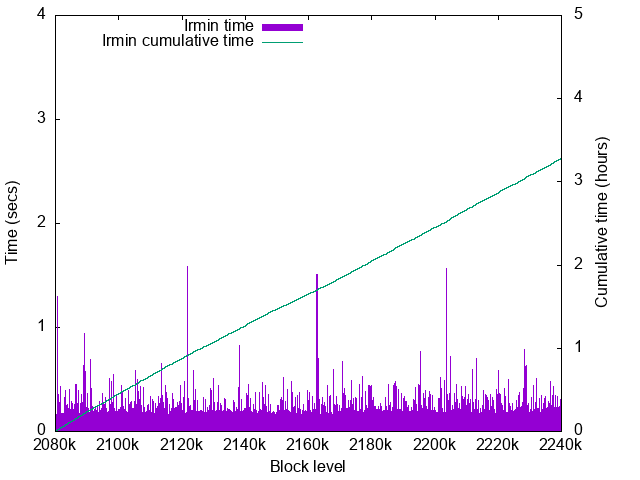
The both systems have their peak times at Tezos cycle bondaries. The number of live context objects verifies that actually Tezos performs lots of file writes at the cycle changes.
Disk size growth
- Plebeia disk size: 5.496 GiB → 49.259 GiB
- Irmin start disk size: 3.486 GiB → 62.101 GiB
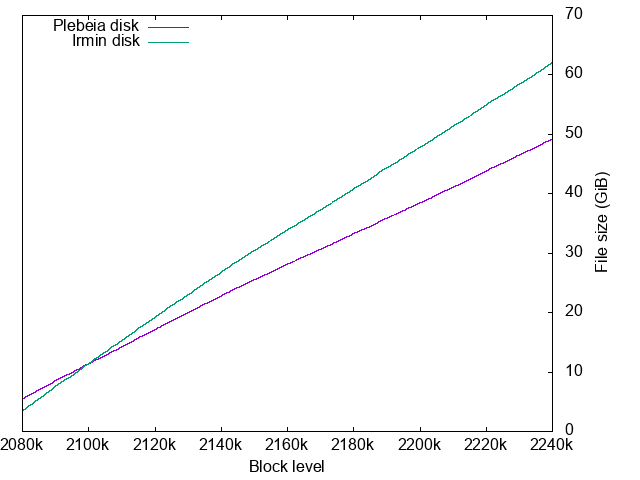
Plebeia disk growth is less steap mainly thanks to its compressed encoding of path names.
For hexdigit path names like af23bc8e12..., Plebeia uses its binary representation to halve the encoding size.
Though Plebeia uses less disk than Irmin, its starting disk usage is larger. This is because Plebeia does not perform any hashconsing. Hashconsing at the snapshot import could help the initial disk size of Plebeia context.
Memory usage
For Irmin RSS is measured for its memory usage.
For Plebeia, RSS is not a good indication of its memory usage. Plebeia uses a memory mapped file and RSS includes the amount of its page cache. Cached pages are freed automatically by the kernel when more memory is required for the processes in the possible cost of more page faults. Here we use $RSS - virtual\ shared\ memory$ for Plebeia memory usage. (This also excludes the size of the linked shared libraries but they are constant.)
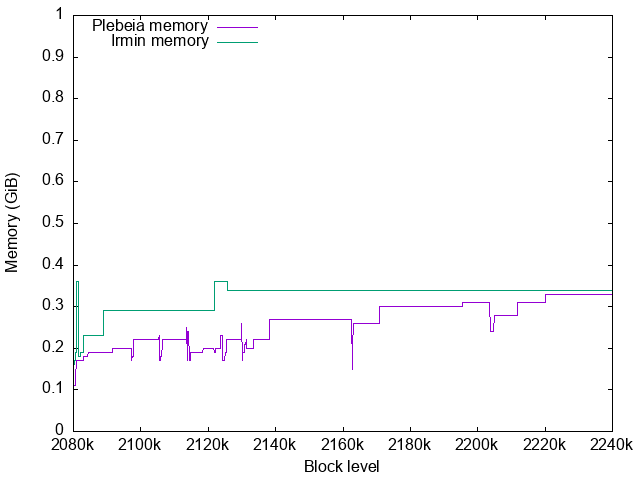
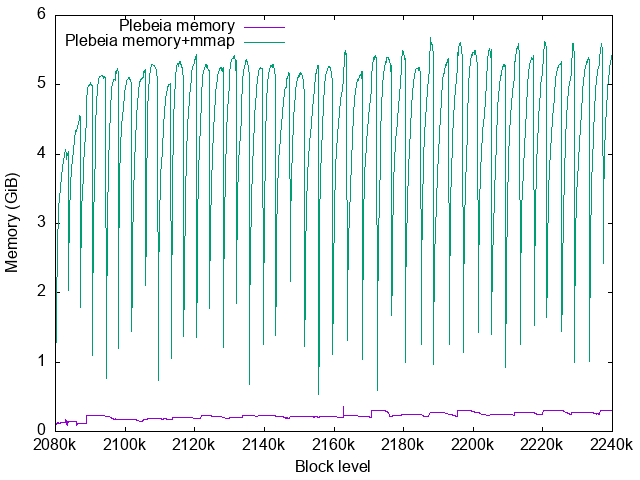
Plebeia memory usage
Plebeia’s RSS is shown in green here. Purple is $RSS - virtual\ shared\ memory$.
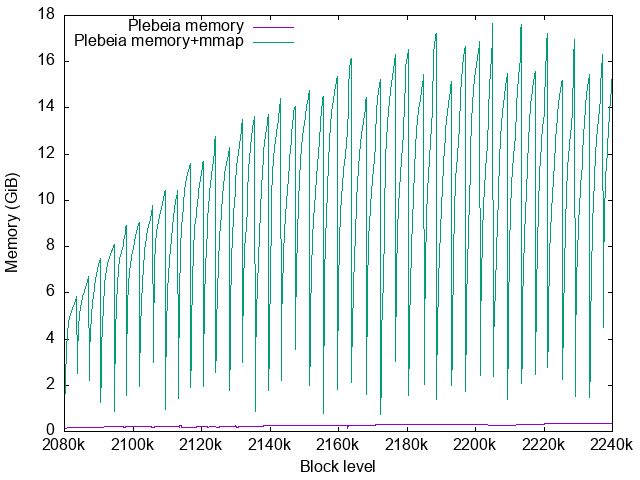
The periodical steep falls of the RSS corresponds with the Plebeia context file resizes. Currently the memory map is created via OCaml’s Unix.map_file which does not support file expansion well. Each time the Plebeia context file is resized, it must munmap() the file and mmap() it again. It unfortunately resets the process’s page table for the mmap and its page cache is lost.
This unnecessary page cache loss should increase the page faults and degrade the performance of Plebeia. To prevent it we need to implement a better mmap library for OCaml with some C code.
Live context objects
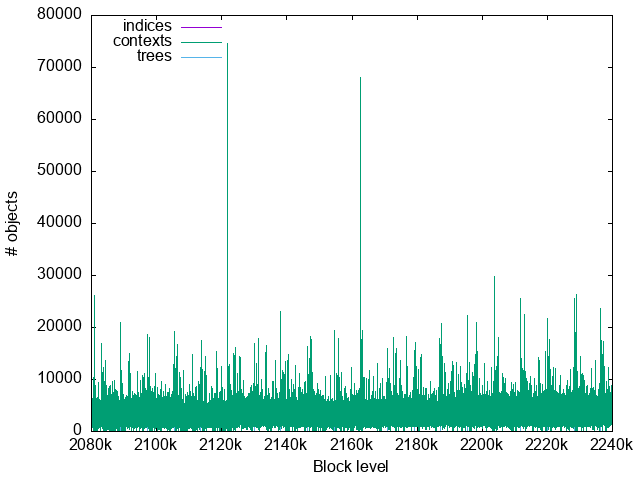
This shows the number of context objects alive in the memory at replay, showing how many context writes happen in each block. This corresponds with Irmin and Plebeia block processing times very well.
There are very large peaks over 30000 objects every 5 cycles. There are also medium sized peaks for each cycle boundary. They correspond with the roll management at the cycle boundaries.
Benchmark using a 16GB machine
Machine spec
- Intel NUC
- CPU: Intel(R) Core(TM) i7-10710U CPU @ 1.10GHz
- Memory: 16GB
- Disk: SanDisk SDSSDH3 1TB
Block processing times
- Plebeia: 3.44 hours for 160001 blocks
- Irmin: 4.62 hours for 160001 blocks
Plebeia time details
- Worst time: 2.56sec
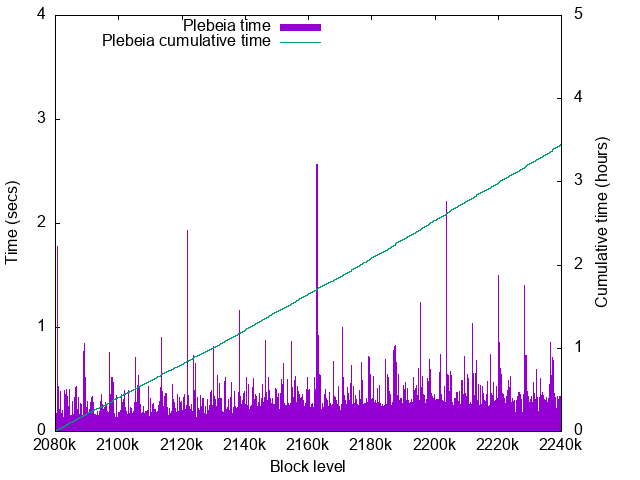
The performance slightly degrades for later blocks. This is due to the context file growth. In later blocks, data are stored more sparcely on the disk. Therefore Plebeia needs to load more disk blocks. Here should be more page faults than the 32GB machine benchmark.
Irmin time details
- Worst time: 2.82sec
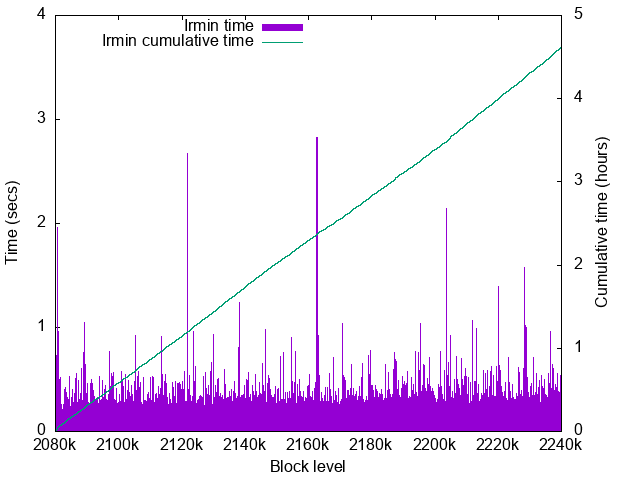
Disk size growth
Same as the 32GB benchmark.
Memory usage
For Irmin RSS is measured for its memory usage.
For Plebeia, the same remakrks at the previous benchmark. We use $RSS - virtual\ shared\ memory$ for Plebeia memory usage.
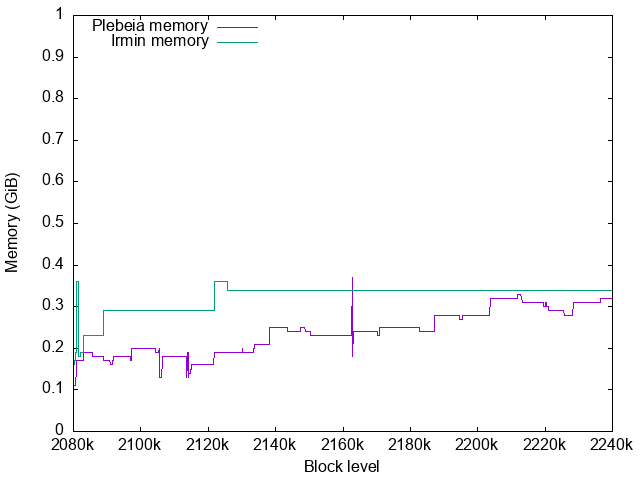
Plebeia memory usage
Plebeia’s RSS is shown in green here. Purple is $RSS - virtual\ shared\ memory$.
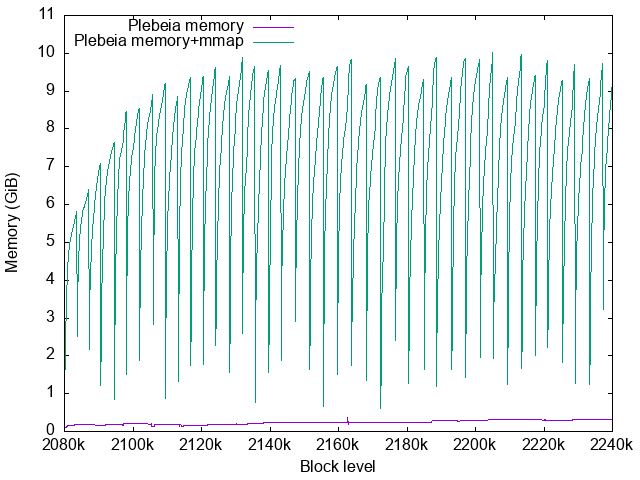
The growth of the page cache for the memory map is culled around 10GB.
Benchmark using a 8GB machine
Machine spec
Same machine as 16GB benchmark. TotalMemory is restricted to 8GB:
- Intel NUC
- CPU: Intel(R) Core(TM) i7-10710U CPU @ 1.10GHz
- Memory: 16GB, Kernel’s TotalMemory is restricted to 8393572 kB
- Disk: SanDisk SDSSDH3 1TB
Block processing times
- Plebeia: 3.79 hours for 160001 blocks
- Irmin: 5.23 hours for 160001 blocks
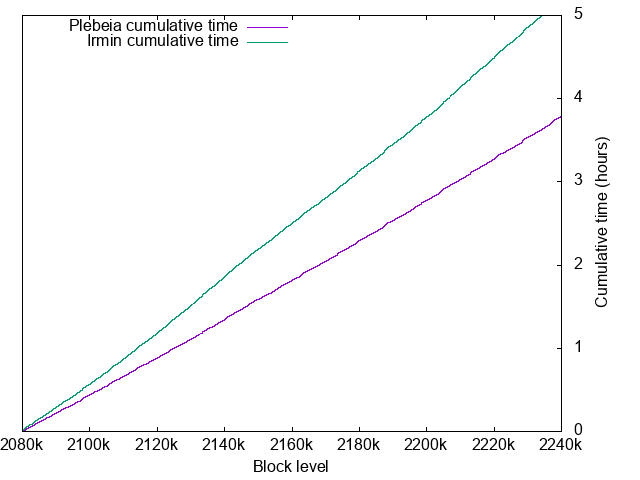
Plebeia time details
- Worst time: 2.48sec
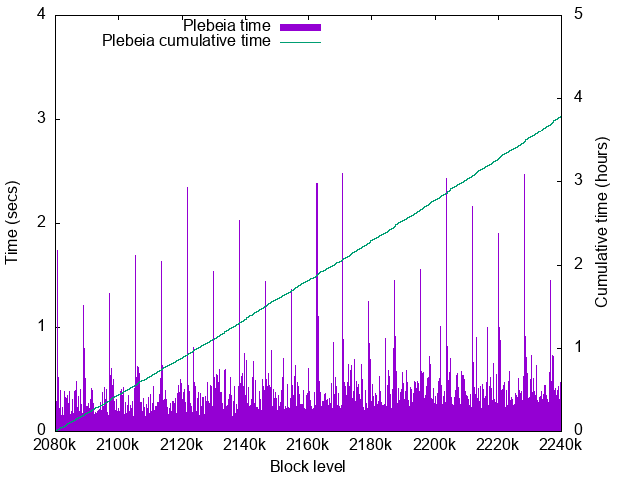
The performance slightly degrades for later blocks.
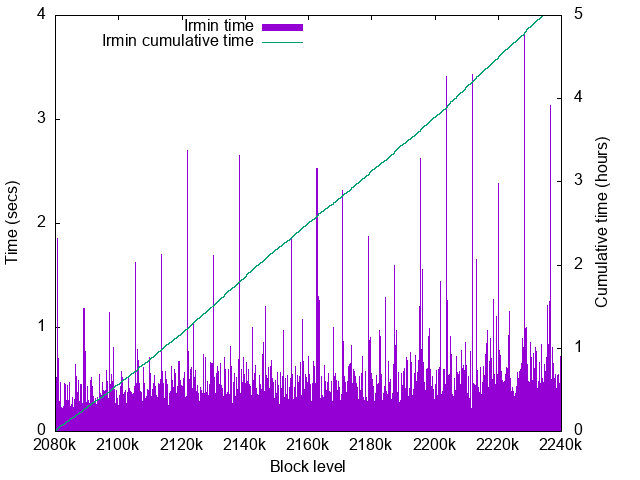
Irmin time details
- Worst time: 3.83sec
Disk size growth
Same as the 32GB benchmark.
Memory usage
For Irmin RSS is measured for its memory usage.
For Plebeia, the same remakrks at the previous benchmark. We use $RSS - virtual\ shared\ memory$ for Plebeia memory usage.
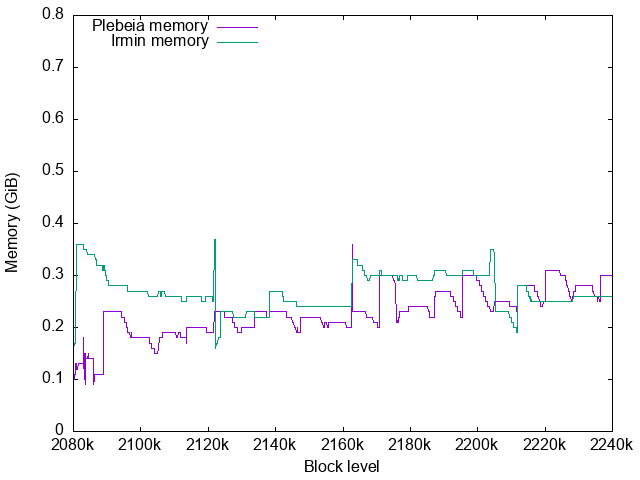
Plebeia memory usage
Plebeia’s RSS is shown in green here. Purple is $RSS - virtual\ shared\ memory$.
Page cache is even more limited in 8GB machine around 5.5GB.
Observation
Performance
We think the difference of the block processing speeds comes mainly from their rates of the disk size growth. Plebeia achieves its lower rate of disk size growth by doing and not doing the followings:
- Path compression: Plebeia uses compact path name representation to reduce the number of its Patricia tree nodes. Tezos context uses very small set of directory names such as
contracts,big_maps,indexexcept the digit and hexdigit directory names. Plebeia replaces these keywords by 4 bytes hashes. For hexdigit (and digit) path names likeaf23bc8e12..., Plebeia uses its binary representation to halve the encoding size. - Lack of pagination information: Plebeia node does not keep the number of the files below it. See the next section for details.
The path compression has greatly reduced Plebeia disk growth rate. We expect that it could reduce Irmin’s context size a lot as well. We have shared this with Tarides and they have done some research already.
Pagination
The current Tezos context records the number of the files found below for the pagination. Plebeia context does not have this, therefore it does not support pagination in RPC. The block validation has no problem since the protocols do not use pagenation so far.
We can add this feature to Plebeia by adding the number of subnodes. But it might worsen the perfomance: we have to add a 32bit integer field to each Plebeia node to count the number of files under it. This would increase the disk usage by 12.5%, which might slow down the whole system by the same percentage.
Page cache usage
Plebeia cannot make full use of the page cache currently. The page cache for the memory map is reset at each context file expansion. Avoiding these resets should reduce the number of page faults and improve the performance of Plebeia. We would require to write a new library to support smooth mmap’ed file expansion.
Plebeia disables read-ahead of the memory map, since its disk access pattern is not sequential but rather random or backward. Indeed, the read-ahead worsened the performance in 8GB machine, likely since it reads unnecessary disk blocks.
Irmin does not use memory mapped file. If it does not disable read-ahead for the context file accesses, it may be worth trying it.
Maximum number of commits per file
It is known that the both systems do not scale well when their context files grow too much, i.e. in archive nodes. Indeed, this benchmark shows that their performance starts slightly degrading after 120,000 blocks. On the other hand, it shows that the both work fine under 100,000 commits in the file.
We could keep the peformance by using layered context storage and moving away older commits to other files. Tarides is working on this layered context and should be available soon. We are also testing layers in Plebeia.
Context time vs the overall time
While the trace replay of the vanilla v13.0 replays 160,000 blocks in 3.28h, the same blocks require 19.2h to be validated by a v13.0 node on the same machine using replay+reconstruct. This big difference is due to the difference of what they measure:
- Trace replay: No network delay, store access, nor block validation.
- Replay+reconsruct: Only without network delay and store write.
The context subsystem uses at most 17% time of the whole Tezos node. It is still a big part of the total cost but this indicates that the other components of the node should also be visited for opimitization for the overall node performance.
How to reproduce the benchmarks
Installation of Tezos+Plebeia node
$ git clone https://gitlab.com/dailambda/tezos
$ cd tezos
$ git checkout jun@v13.0-plebeia-ithaca-trace
$ ./0build.sh
Benchmark preparation
Trace for replay
Use Tezos+Plebeia’s tezos-node to record a trace for block replay:
- Use
CONTEXT_RECORD_TRACE=<TRACE_FILE>env var to specify the file to save the trace. - Use
--singleprocess. - Use
--range <LEVEL1>_<LEVEL2>to specify big range of blocks. - Use
CONTEXT_SUBSYSTEM=IrminOnlyto disable Plebeia context, which is not required to make a trace.
$ CONTEXT_SUBSYSTEM=IrminOnly \
CONTEXT_RECORD_TRACE=trace_2080000_2240000 \
./tezos-node replay \
--singleprocess \
--data-dir archive_node_data_dir \
--range 2080000_2240000
Source context
Import a snapshot of the starting level using Tezos+Plebeia node binary:
$ mkdir source_context
$ ./tezos-node snapshot import --data-dir source_context snapshot-2080000.full
After the import of the snapshot, it converts the context to Plebeia. It takes some time. After a successful import, plebeia.commit_tree and plebeia.context files should be found under the directory:
$ ls source_context
context/ lock plebeia.commit_tree plebeia.context plebeia.lock \
store/ version.json
Keep this source context directory untouched.
Test context
For each benchmark run, copy the source context to a new directory, since each run overwrites the files:
$ mkdir test_context
$ cp -a source_context/context source_context/plebeia* test_context
Benchmark replay
To replay with Irmin context:
$ CONTEXT_SUBSYSTEM=IrminOnly \
nohup dune exec tezos-replay-trace/tezos_replay_trace.exe replay \
trace_2080000_2240000 \
test_context/context \
2240000 > log_irmin_only 2>&1 &
tezos_replay_trace.exe prints out various metrics to the log file.
To replay with Plebeia context, not forgetting to prepare a new test directory:
$ CONTEXT_SUBSYSTEM=PlebeiaOnly \
PLEBEIA_SYNC_SECONDS=20 \
nohup dune exec tezos-replay-trace/tezos_replay_trace.exe replay \
trace_2080000_2240000
test_context/context
2240000 > log_plebeia_only 2>&1 &
Currently PLEBEIA_SYNC_SECONDS=20 is required for the best performance. This will be default in future version of Tezos+Plebeia.
–>