Plebeia is a functional storage system using Merkle Patricia tree implemented purely in OCaml. It is meant to be used for Tezos blockchain.
Here are our updates since the last article:
- Optimized the storage size down to 80% since the last version, using its refactored path conversion scheme and hash-consing.
- Less than 70% of the current Tezos storage size by Irmin2.
The code of Plebeia is available in GitLab. Plebeia integrated Tezos node is also available.

Some recap
Blockchain is a ledger style database where the current state of the DB is expressed as an accumulation of small commits since the initial state. Unlike the classical ledgers such as bank books, a blockchain can diverge: the state can have branches like version control systems. Trees are often used to store such data structures.
A blockchain state stored in a tree is secured by Merkle hashes attached to the nodes, whose values are defined recursively by computing hashes of the concatenation of the hashes of their sub-nodes. Only with the root Merkle hash of a tree, clients can verify the integrity of the server response about the tree trustlessly. Here, we reach to the notion of Merkle trees, a tree whose nodes are attached with Merkle hashes.
Merkle trees are very sparse and it is very inefficient to implement them via trie. Patricia tree is used instead to reduce the number of internal nodes.
Plebeia is an implementation of Merkle Patricia tree, with several optimizations:
- Fixed width node data layout
- Implementing a Patricia tree most trivially makes space required for its constructs unbalanced, which leads to a huge increase of unused space on disk or a complex space fitting algorithm. Arthur Breitman has proposed a nifty idea to split Patricia tree’s internal node into 2 sub-categories, Internal for branching and Extender for long path. This balances the space requirements of the node constructs and permits a simple fixed-sized “cell” management on disk without incurring a huge amount of unused disk space.
- Fast Merkle hash generation for longer paths
- Cryptographic hash calculation is not a cheap operation and therefore should be avoided as far as hash collision attack is impossible. We simplified the hash calculation of Extenders which is the concatenation of the hash of its sub-node and the path, which makes their hashes with variable lengths. This is inspired by the idea described by Vitalik Buterin.
Recent updates of Plebeia
SWMR
Tezos Mainnet December 2019 has introduced the external validation process. The validation process is the writer of the blockchain state. The other main process is the reader.
Plebeia was a single process DB where only one process could read and write it. To follow the Tezos Mainnet December 2019, it is extended to SWMR (single writer multiple readers). Since Plebeia is an append-only DB we can achieve it without any lock mechanism: each time a reader wants to get the latest commit by the writer, it checks the commit list for any update.
Hash consing nodes
Blockchain databases carry a lot more small data than the usual file systems and they are often identical. Squashing identical nodes by hash consing can save significant space of persistent storage.
We had hash consing for a while but it was based on a quickly written naive heuristics, which did not demonstrate optimal performance. We have refactored it over a proper probabilistic model aiming to maximize its efficiency. Now the on memory cache of small data from 1 to 36 bytes limited to 100MB saves few GBs of the entire 30GB on disk.
We also have a small on memory cache for internal node hash consing for directories, which contributes small size reduction.
New path conversion
Tezos path
In Tezos, values of block chain states are placed in files and they are arranged in a Unix like directory hierarchy. Since its genesis, Tezos has the following path name schema:
/data/active_delegates_with_rolls/<Public_key_hash>
/data/big_maps/index/<N>/contents/<Script_expr_hash>/len|data
/data/big_maps/index/<N>/key_type
/data/big_maps/index/<N>/total_bytes
/data/big_maps/index/<N>/value_type
/data/big_maps/next
/data/big_maps/next
/data/block_priority
/data/commitments/<Blinded_public_key_hash>
/data/contracts/global_counter
/data/contracts/index/<Contract_repr2>/big_map/<Script_expr_hash>/len|data
/data/contracts/index/<Contract_repr2>/data/storage|code
/data/contracts/index/<Contract_repr2>/delegated/<Contract_hash2>
/data/contracts/index/<Contract_repr2>/delegated/<Contract_hash>
/data/contracts/index/<Contract_repr2>/delegated_004/<Contract_hash2>
/data/contracts/index/<Contract_repr2>/delegated_004/<Contract_hash>
/data/contracts/index/<Contract_repr2>/frozen_balance/<Cycle_repr>/fees|rewards|deposits
/data/contracts/index/<Contract_repr2>/len/storage|code
/data/contracts/index/<Contract_repr2>/used_bytes|paid_bytes|delegatable|inactive_delegate|roll_list|delegate_desactivation|delegate|change|spendable|manager|counter|balance
/data/contracts/index/<Contract_repr>/big_map/<Script_expr_hash>/len|data
/data/contracts/index/<Contract_repr>/data/storage|code
/data/contracts/index/<Contract_repr>/delegated/<Contract_hash>
/data/contracts/index/<Contract_repr>/frozen_balance/<Cycle_repr>/fees|rewards|deposits
/data/contracts/index/<Contract_repr>/len/storage|code
/data/contracts/index/<Contract_repr>/used_bytes|paid_bytes|delegatable|inactive_delegate|roll_list|delegate_desactivation|delegate|change|spendable|manager|counter|balance
/data/contracts/old_index/<Contract_repr>/big_map/<Script_expr_hash>/len|data
/data/contracts/old_index/<Contract_repr>/data/storage|code
/data/contracts/old_index/<Contract_repr>/delegated/<Contract_hash>
/data/contracts/old_index/<Contract_repr>/frozen_balance/<Cycle_repr>/fees|rewards|deposits
/data/contracts/old_index/<Contract_repr>/len/storage|code
/data/contracts/old_index/<Contract_repr>/used_bytes|paid_bytes|delegatable|inactive_delegate|roll_list|delegate_desactivation|delegate|change|spendable|manager|counter|balance
/data/cycle/<Cycle_repr>/last_roll/<Int_index>
/data/cycle/<Cycle_repr>/nonces/<Raw_level_repr>
/data/cycle/<Cycle_repr>/random_seed|roll_snapshot
/data/delegates/<Public_key_hash>
/data/delegates_with_frozen_balance/<Cycle_repr>/<Public_key_hash>
/data/genesis_key
/data/last_block_priority
/data/protocol_parameters
/data/ramp_up/deposits/<Cycle_repr>
/data/ramp_up/rewards/<Cycle_repr>
/data/rolls/index/<Roll_repr>/successor
/data/rolls/limbo
/data/rolls/next
/data/rolls/owner/current/<Roll_repr>
/data/rolls/owner/snapshot/<Cycle_repr>/<Int_index>/<Roll_repr>
/data/sandbox_parameter
/data/v1/constants
/data/v1/first_level
/data/version
/data/votes/ballots/<Public_key_hash>
/data/votes/current_period_kind
/data/votes/current_proposal
/data/votes/current_quorum
/data/votes/listings/<Public_key_hash>
/data/votes/listings_size
/data/votes/participation_ema
/data/votes/participation_ema
/data/votes/proposals/<Protocol_hash>/<Public_key_hash>
/data/votes/proposals_count/<Public_key_hash>
/message
/protocol
/test_chain
/time
s1|s2 is an or-pattern which matches one of s1 and s2. <name> is called index (by me) since it is numbered by hex chars, integers, and/or fixed number of keywords. For example, <Contract_repr2> is multi directory path names which match with the following regular expression:
[0-9a-f]{2}/[0-9a-f]{2}/[0-9a-f]{2}/[0-9a-f]{2}/[0-9a-f]{2}/[0-9a-f]{30}
For example, path /data/contracts/index/ff/34/b1/84/ee/b2/0000b985218d96c52a2d4680ebbaa88ae6429dffc64e/balance matches with the following pattern:
/data/contracts/index/<Contract_repr2>/used_bytes|paid_bytes|delegatable|inactive_delegate|roll_list|delegate_desactivation|delegate|change|spendable|manager|counter|balance
Path conversion
To store Tezos blockchain states, each file path of Tezos is converted to segments, edge label sequences of a Plebeia tree.
As far as its bijection is assured, it is not required at all for the path conversion to keep the same directory structure of Tezos, which have many directory levels. If the path conversion can produce less Plebeia tree nodes, we can decrease the size of the storage immediately, since having 1 more directory in Plebeia leads to 2 more internal nodes in the tree which cost 64bytes on disk.
The previous version of this path conversion was somewhat trivial: it kept Tezos directory hierarchy in Plebeia almost as they were. Today we have about 500K contracts(accounts) stored under <Contract_repr2> in Tezos Mainnet using 2.5M directories. For one snapshot of a commit, 160MB of disk space was required for it with the previous path conversion. Though Plebeia shares sub-trees between commits as possible, this cost is not negligible.
New conversion with directory compression
Our new path conversion concatenates directory components to lower down the number of directories. Consecutive indices (<name> things) are concatenated to one binary. Consecutive non indices are replaced by the 4 byte identifier of their concatenated names. For example, the above path /data/contracts/index/ff/34/b1/84/ee/b2/0000b985218d96c52a2d4680ebbaa88ae6429dffc64e/balance is converted to segments: /0x40c04a88/0xff34b184eeb20000b985218d96c52a2d4680ebbaa88ae6429dffc64e/0xc245d896 where
0x40c04a88is the identifier for"data/contracts/index"0xc245d896is the identifier for"balance"
These identifiers are defined basically by their hashes.
As you can see, <Contract_repr2> has no internal directories in this new conversion. We now need about 2M fewer directories for 500K contracts. This new path conversion with this directory compression made the data file size about 85% of one with the previous version.
Performance
Here is a comparison of disk usages of both systems: Irmin2 (the current one used by Tezos) and Plebeia, bootstrapping from the genesis of Mainnet in the full archive mode:
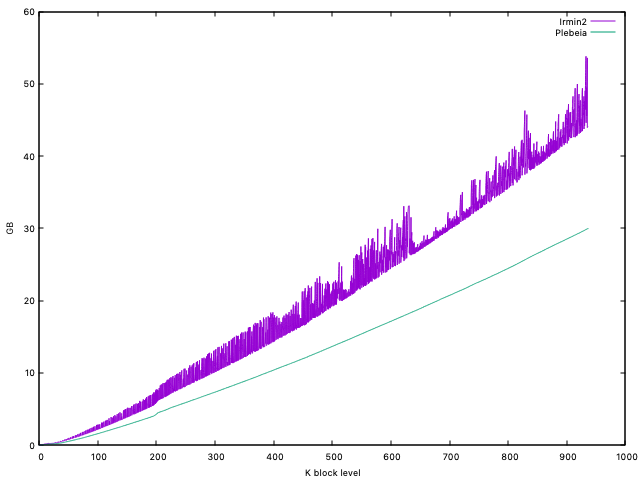
The disk usage of Plebeia is less than 70% of Irmin2’s lower bound. For example, the disk sizes of block level 938606 today are 29G for Plebeia and 42G for Irmin2.
While the usage of Irmin2 always fluctuates around 17% of itself, Plebeia’s usage curve is very smooth, since this is a purely append-only system except for the first 64 bytes header. The disk I/O of Plebeia is much lighter, but to be fair, this is partially thanks to the current lack of garbage collection.
Correctness
We have formally proven the following properties:
- The invariants of Plebeia nodes are preserved by the tree operations.
- The correctness of insert/upsert/removal of data/directory of Plebeia trees.
- The security of Merkle hash calculation: there is no easy way to make a node whose hash collides with the others unless Blake2 algorithm itself is bleached.
Tezos integration is checked operationally: we build a Tezos node that runs 2 storage subsystems (Irmin2 and Plebeia) in parallel and performs the same operations over them. For each read operation, the results from the 2 systems are compared. Bootstrapping the node from the genesis to today’s head, we have never seen any conflicts between them.
The code
Plebeia integrated Tezos node is available at our repository. Please check README_Plebeia.md for how to build and run it.
The code is written for the full archive mode but it should work for other modes, too. You can try it using the existing data files: if Plebeia finds missing commits in its file, it emulates them using Irmin2. When the emulated commit is updated and recommitted as another commit, Plebeia copies all the necessary data from Irmin2. It usually takes several minutes and lots of disk accesses. Please be patient.
Further development
Port to Version 7.0
Integration is currently done against Mainnet January 2020, which was just superseded by Version 7.0. First of all, we will upgrade our integration to 7.0.
GC and tools
This is our next main task.
Abandoned branches, and garbage data resulted from node crashes, and too old states may become unnecessary and be removed from the disk: we need a GC, preferably concurrent one. The main challenge is how to reduce the disk usage for the intermediate states and the I/O pressure.
The tool for snap-shotting is also required, but this one is obtained almost for free from a copy GC algorithm.
Plebeia core specification
The logical specification and a layout on disk are defined. This part will unlikely change unless any security flow around Merkle hash calculation is found.
Plebeia core implementation
This part is well tested and some key algorithms are formally proven by F* and Coq. We continue to prove some more. We hope we can write more about it here and in an academic paper soon.
Optimizations
Currently, hash cons-ing is performed only for small leaves and Buds (directories of Plebeia). We may extend this to other internal nodes if it has a positive impact.
In Tezos, it is quite common that a value is updated just after its read. Currently, some of the same computations are done twice at the read and the write. We may be able to optimize the performance by remembering the computations done by recent reads.
Path conversion
The new path conversion squashes Tezos directories and it requires non-trivial Plebeia tree investigations: many directories do no longer have the corresponding Plebeia nodes in the tree: instead they become midpoints over Patricia edges. These operations are well tested but subtle, therefore formal proofs of their correctness are required.
The path conversion must know the schema of Tezos states, all the possible paths of it. Currently, they are manually extracted from Tezos source such as storage.ml. This is error-prone and happens for each Tezos protocol upgrade. It would be nice if they are automatically obtained.
Toward the final integration
Plebeia now works fine with Tezos but it is still experimental: the node still uses the context hash (hash of a blockchain state) of Irmin2, and the context hash of Plebeia is NOT compatible with it. If we migrate to Plebeia, then it requires a protocol change to switch the context hash from the current one to Plebeia.
This must be done carefully since it takes a long time to prepare Plebeia storage: making a snapshot from the current storage takes several minutes. To bootstrap from the genesis, it takes a few days. If all the nodes switch to Plebeia at the same time without any preparation, the entire network stalls for a real long time. We cannot allow it to happen.
We will have to design a coordinated scheme so that each node can prepare the migration gradually. Once enough number of nodes become ready for migration, we can switch the hashing at some point. We can vote the timing by a protocol amendment or even let the protocol decide it automatically (of course we need to upgrade the protocol in advance for it.)
Since Plebeia cannot produce the current context hash, it cannot validate the past commits. Therefore we will have to keep both storage subsystems in the node. Currently, Irmin2 and Plebeia are completely independent but now I believe that they can cooperate. For example, Plebeia’s value storage, and commit management are not fully optimized. They could be replaced by Irmin’s. Then Plebeia could concentrate to provide a simple, formally verified and optimized Merkle Patricia tree implementation.